
Au commencement était l’indexation du site web
Comme ces pêcheurs à pied parcourant la plage pour trouver des coquillages, les robots d’indexation parcourent les pages web sans relâche, pour découvrir les nouvelles et pour mettre à jour les plus anciennes (Crédit photo : ©Côté Manche). Avant même de parler de référencement, il y a une première étape à respecter : l’indexation. Comment espérer avoir des pages web correctement positionnées dans les SERP (Search Engine Results Pages/pages de résultats de moteur de recherche) si elles ne sont même pas connues par les moteurs de recherche ?
L’indexation consiste à faciliter le travail des robots pour trouver de nouvelles pages et de nouveaux contenus. Elle est donc un préalable indispensable au référencement naturel et au (bon) positionnement.
Faire ami-ami avec les robots d’indexation
 Toute la question est de faciliter et de favoriser l’indexation des pages d’un site, et pas nécessairement toutes les pages d’un site, d’ailleurs. Deux conditions à remplir pour que l’opération se déroule gentiment : faciliter le travail du {crawler|bot|spider} pour qu’il parcoure le site sans ralentissement ni heurt, et lui indiquer clairement toutes les pages que l’on souhaite lui présenter pour qu’il les gloutonne et les indexe. En complément, il est possible de lui signifier quels éléments du site on souhaite ne pas voir crawlés.
Toute la question est de faciliter et de favoriser l’indexation des pages d’un site, et pas nécessairement toutes les pages d’un site, d’ailleurs. Deux conditions à remplir pour que l’opération se déroule gentiment : faciliter le travail du {crawler|bot|spider} pour qu’il parcoure le site sans ralentissement ni heurt, et lui indiquer clairement toutes les pages que l’on souhaite lui présenter pour qu’il les gloutonne et les indexe. En complément, il est possible de lui signifier quels éléments du site on souhaite ne pas voir crawlés.
Les liens sont bien créés
Le {crawler|spider|bot} d’indexation se déplaçant grâce aux liens hypertextes, les pages à indexer doivent bien évidemment lui être accessibles grâce à des liens. La navigation, sur le site, doit rendre ces pages parcourables.
Le site possède son fichier sitemap.xml
Ce fichier permet d’indiquer clairement aux crawlers les pages qu’ils doivent absolument parcourir lors de leur passage. Il comporte donc la liste des URLs que l’on souhaite voir indexer.
La synthaxe du fichier est celle-ci :
<?xml version="1.0" encoding="UTF-8"?>
<urlset>
<url>
<loc>https://www.monsite.fr/mapageimportante.html</loc>
</url>
<url>
<loc>https://www.monsite.fr/uneautrepageimportante.html</loc>
</url>
</urlset>
Il fut un temps où ajouter pour chaque URL la date de dernière modification et la priorité de la page par rapport aux autres était utile. L’évolution des bots et des moteurs de recherche a rendu la manipulation caduque.
Une fois le fichier créé – et il existe tout plein de générateurs de sitemap en ligne – il ne reste qu’à déposer le fichier à la racine du site web, sur le serveur. Logiquement, les crawlers vont automatiquement aller vérifier la présence de ce fichier sitemap.xml. Mais pour être tout à fait certain qu’ils vont bien le trouver, il est possible de forcer l’opération en déclarant directement le fichier aux services de Google, Bing et consorts. En ce qui concerne le moteur le plus utilisé en France, l’interface pour déclarer un fichier sitemap.xml est la « Search Console ».
Les robots trouvent leur robots.txt
Un autre moyen de montrer clairement aux bots que le fichier sitemap.xml existe est d’indiquer son emplacement dans le fichier robots.txt en ajoutant la ligne suivante (à adapter à chaque Nom de Domaine) :
sitemap: https://www.monsite.fr/robots.txt
Le fichier robots.txt doit obligatoirement porter ce nom exact, car les robots vont le chercher à leur arrivée sur un site web. Le nom robot.txt n’est pas correct et les bots passeront outre. En outre, le fichier doit être placé à la racine du site web.
 Ce fichier permet également d’interdire (théoriquement) aux crawlers certaines portions du site. Il permet également de donner des instructions particulières à chaque robot connu. Le robot d’indexation de Google répond au doux nom de Googlebot, tandis que son cousin dédié aux images s’appelle Googlebot-Image. Le crawler de Bing a été baptisé Bingbot quand celui de Baidu (moteur de recherche chinois) se prénomme Baiduspider.
Ce fichier permet également d’interdire (théoriquement) aux crawlers certaines portions du site. Il permet également de donner des instructions particulières à chaque robot connu. Le robot d’indexation de Google répond au doux nom de Googlebot, tandis que son cousin dédié aux images s’appelle Googlebot-Image. Le crawler de Bing a été baptisé Bingbot quand celui de Baidu (moteur de recherche chinois) se prénomme Baiduspider.
Dans ce fichier robots.txt, s’adresser à tous les robots nécessite la syntaxe suivante :
User-agent: *
Disallow: /dossierprive
L’instruction demande à tous les robots de ne pas parcourir le dossier intitulé « dossierprive ». Cette consigne doit être répétée pour chaque élément du site à bloquer, en ajoutant une ligne avec la même syntaxe.
S’adresser à un bot en particulier, à celui de Baidu dans l’exemple ci-dessous, nécessite la syntaxe suivante :
User-agent: Baiduspider
Disallow: /dossierprive[PRO TIP]
Début mars 2018, John Mueller (Webmaster Trends Analyst chez Google) répond à la question « How Often Google Reindexes A Web Site? »
Looking at the whole website all at once or even within a short period of time can cause a significant load on a website. Googlebot tries to be polite and is limited to a certain number of pages every day. This number is automatically adjusted as we better recognize the limits of a website. Looking at portions of a website means that we have to prioritize how we crawl.
So how does this work? In general, Googlebot tries to crawl important pages more frequently to make sure that most critical pages are covered. Often this will be a websites home page or maybe higher-level category pages. New content is often mentioned and linked from there, so it’s a great place for us to start. We’ll recrawl these pages frequently, maybe every few days. maybe even much more frequently depending on the website.
John est très clair : en ce qui concerne Googlebot, c’est Google qui détermine les zones importantes du site à visiter le plus souvent, et plus particulièrement les pages de haut niveau. Toujours d’après John Mueller, le robot ne parcoure pas toutes les pages pour ne pas saturer le serveur, étant capable de mesurer la charge supportée par celui-ci.
On peut également conclure de cette déclaration que les conditions d’hébergement (le serveur) jouent un rôle prépondérant dans les visites des bots d’indexation : si le site supporte une charge importante, les crawlers parcourent plus de pages.
Les robots parcourent un site rapide
Dans la droite ligne de ce qu’annonce John Mueller, qu’un serveur doit offrir un environnement robuste au site web, le serveur doit également présenter des caractéristiques de vitesse les plus élevées possibles, afin que les robots parcourent librement les pages, et indexent rapidement leur contenu.
Les ressources matérielles des moteurs n’étant pas illimitées, leurs robots d’indexation n’ont pas des heures à consacrer au parcours et à l’indexation de chaque site. C’est de cette limite qu’est né le concept de Crawl Budget. Leur permettre de parcourir beaucoup de pages en un temps limité est pertinent, et est très probablement un signe positif à envoyer aux moteurs. Peut-être nous en seront-ils reconnaissants, plus tard, au moment du positionnement ?
Pour s’assurer un serveur performant, il est nécessaire d’écarter d’office les offres à très bas coût sur des serveurs mutualisés. Partager un serveur avec plusieurs centaines d’autres sites empêche logiquement d’atteindre des performances intéressantes. Et les conditions techniques sont possiblement bridés pour limiter les risques de surchauffe.
Le charme des travaux manuels
Lorsqu’une nouvelle page est créée sur un site web, et qu’elle est ajouté à des fins stratégiques, la faire indexer rapidement est essentiel. Conscients de cela, les principaux moteurs de recherche mettent à disposition des éditeurs de site et des webmasters des outils de soumission manuelle : grâce à eux, il est possible de demander directement aux crawlers de venir parcourir de nouveaux contenus et de les indexer.
Vérifier comment les robots parcourent un site
Un serveur web Apache, le plus répandu pour héberger des sites web, enregistre toutes les visites sur les différents sites Internet qu’il héberge. Et il a la bonne idée de noter également qui demande à afficher ces pages. Il est donc possible, en étudiant ce fichier-journal de connexions appelées « logs », de savoir quel robot visite le site, à quel moment, et quelles pages il parcoure. Deux informations intéressantes sont à extraire de l’analyse de ces logs : la fréquence de passage de tel ou tel bot, ainsi que les zones du site qu’il préfère.
Dans le cas où ces informations ne coïncident pas avec la stratégie de référencement naturel prévue, il est donc possible de rectifier le tir.
Vérifier le bon déroulement de l’indexation
Google fournit, dans la nouvelle version de sa Search Console, la liste des pages qu’il a indexé. Cerise sur le gâteau, il donne également la liste des pages qu’il n’a pas ajouté à son index, et surtout la raison pour laquelle ces pages sont refusées. Des informations particulièrement intéressantes à exploiter, qui permettent de suivre l’évolution de l’indexation, et pour y apporter d’éventuelles corrections, si nécessaire.
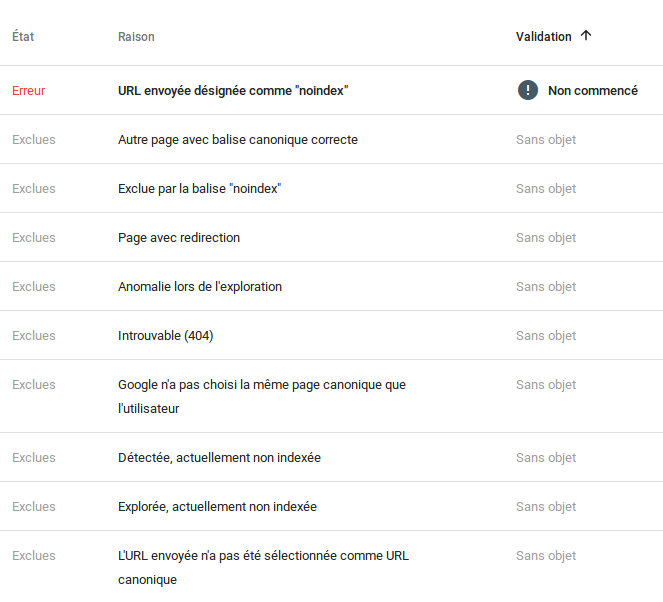
Exemple de liste d’erreurs dans l’indexation des pages, dans la Search Console